Android平台能够使用的数据库无非SQLite和Realm两种,Realm是第三方的响应式移动平台数据库,而SQLite则是Android原生支持的文件数据库。
今天要记录的是SQLite数据库的Orm框架GreenDao3,和EventBus出自同一开源组织,来自于greenrobot。
GreenDao3相对于GreenDao2使用起来更加便捷,是不可多得的兼效率和便捷于一身的SQLite Orm框架。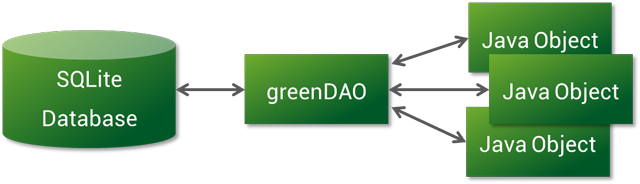
添加Gradle依赖
将下面gradle配置加入到Android项目中
这些配置将greendao插件hook到项目的build进程中,当项目被build的时候,插件会自动构建生成类文件,如DaoMaster,DaoSession和一些Dao
可以在AndroidStudio中通过“build” -> “Make Project”操作进行手动触发构建
一些核心类的概念
经过上面的配置操作,我们就可以在项目中使用greenDao了,下面介绍一些greendao中的核心接口。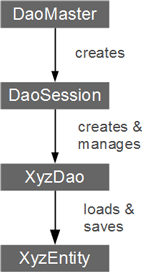
DaoMaster 这个类是使用greenDao的入口,DaoMaster持有着SQLite数据库对象并管理着所有一个schema中的所有Dao类。它有一些静态方法用来创建表和删除表,它的内部类OpenHelper和DevOpenHelper继承自SQLiteOpenHlper用来在SQLite中创建schema。
DaoSession 管理了一个schema中的所有Dao对象,可以通过getter方法获取这些Dao对象。DaoSession提供entity的一些持久化方法如insert,load,update,refresh,delete,这些方法都是由插件自动生成的。
DAOs Data access objects简称Dao,用来对entity的存取访问。针对每一个entity,greendao都会生成一个对应的DAO类,这些类提供了比DaoSession更多的持久化方法,如count,loadAll等
Entity 持久化类,通常情况下一个持久化类对应着数据库中的一张表,每条数据对应着普通的pojo类或者javabean
初始化核心接口
注意:DaoMaster、DevOpenHelper等类是在定义Entity之后由插件生成的,在没有定义并构建Entity的时候是找不到这些类的。
我们需要在程序开始时初始化greenDao并且初始化对应的数据库,通常情况下我们需要初始化一个DaoSession,这个daosession在整个app生命周期中只会初始化一次,所以会写在Application中。
比如这样:
如果我们使用到加密的数据库,可以如下定义:
之后就可以通过Application拿到daoSession的全局实例,并通过getter方法拿到dao对象来进行数据库访问操作了,如:
定义持久化类/实体类
使用greenDao,我们通过定义实体类映射到数据库中的表,并通过实体类来生产Dao层的Java代码。
实体类是通过普通的java类和greendao的注解来进行定义的。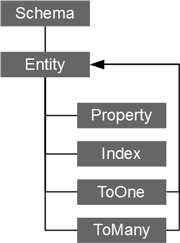
Schema
尽管我们配置过greendao插件之后就可以进行使用了,但是我们最起码要配置上的Schema的版本,这是非常建议的,Schema的版本默认是从1开始的。
此外,greendao还支持很多其他配置
schemaVersion 数据库当前的schema版本,OpenHlopers类通过这个来针对不同版本进行迁移,如果你修改了实体类或者数据库schema,这个值必须要增加,默认是1。
daoPackage 用来指定生成的Dao、DaoMaster、DaoSession类的包名,默认是entity所定义的的包名。
targetGenDir 指定所生成的源码的位置,默认是在build目录下(build/generated/source/greendao)。
generateTests 设置为true会自动生成unit tests。
targetGenDirTests 用来生成unit tests的根目录,默认是src/androidTest/java。
实体类和注解
greenDao3使用注解来定义scheme和实体类,下面是个简单的例子
@Entity注解使这个java类能够被映射到数据库表,同时通知greendao生成一些必要的代码,如Dao类(UserDao)。
注意:这里只支持使用Java类来定义。如果要使用其他jvm语言如kotlin这样的,那么实体类一定要使用java来写。
@Entity注解
正如上面的例子那样,@Entity注解让java类标记为了greendao中持久化类。
使用@Entity时通常不添加任何附加参数,但我们也可以配置一些详细的描述。
Note that multiple schemas are currently not supported when using the Gradle plugin(插件). For the time being, continue to use your generator project.
一般情况也用不上
基础属性
|
|
@Id注解使用一个long/Long类型作为实体ID,在数据库中作为主键,参数autoincrement标识为true时,会让id值不断的增加,不和现有值重复。注意这里,autoincrement只有在Id字段为Long这样可空的包装类型时才能使用,因为long基础数据库类型greendao是无法判断这个字段是否为空的,从而造成greendao无法判断id字段是否是省缺状态的。
@Project可以指定自定义的数据库字段名,如果省缺,则会使用数据库风格的命名,用大写加下划线来代替驼峰命名法,例如customName会转换为CUSTOM_NAME,这里只能使用常量。
@NotNull 让数据表中的一个字段标记为“NOT NULL”,通常情况下用来标记原始的数据类型如long,int,short,byte等,这些类型存在可为null的包装类如Long,Integer,Short,Byte. PS: 感觉官方这个解释好像反了,测试结果是基础数据类型上加不加NotNull都是非空的,莫非是要加载包装类上?
@Transient 让字段排出持久化,不会生成表字段,也可以使用java中的transient来标识。
主键限制
在greendao中实体类必须要使用long或者Long类型来作为主键,这是Android和SQLite推荐的做法。
为了解决这个问题,可以通过定义你的主键为一个额外的字段,并给这个字段创建唯一的索引
字段索引
在一个字段使用@Index注解来创建数据库中对应字段的索引,可以使用如下参数来配置
name 如果你不喜欢greendao生成的索引名字,你可以自己指定
unique 约束索引,强制所有值为唯一的
@Unique 为一个字段添加唯一约束,SQLite会潜在的为这个字段添加一个索引
省缺配置
greendao会尝试使用最合理的省缺配置,所以没有必要为每一个配置项都指定配置。
例如表名和字段名默认情况下是根据实体类的类名和字段名类定义的,将驼峰命名法的命名转换sql中大写字母加下划线的命名风格。
如字段createionDate会转换为CREATION_DATE
映射关系
数据库表可能通过1对1,1对多,多对多的方式进行关联。
greendao使用toone和tomany来实现这些关联,比如想要在greendao中实现1对多的关系,就要用到一个toone和一个tomany关系,而且这一对toone和tomany并没有直接联系,所以需要一起修改和更新。
ToOne关联
@ToOne注解用来定义字段和另外一个实体类的关联,需要放在关联实体类的字段上。
在实体类的内部需要添加一个指向被关联实体类Id字段的字段,这个字段被@ToOne注解的joinProperty属性来指定。如果这个属性被省略,会自动添加一个数据库字段来映射目标实体类的Id。
to-one关系的getter方法(例如getCustomer)会在被初次调用的时候延迟加载实体类,之后再次调用则会立即返回之前的加载结果。
如果修改了外键的值(customerId),再次调用getter方法(getCustomer)将会根据修改后的外键重新查询。
如果设置了新的关联实体类(setCustomer()),外键也会被同时更新。
注意:如果要在加载实体类的时候同时加载被关联的实体类,使用DAO的loadDeep()和queryDeep()方法。这两个方法会在同意一个数据库请求中把关联的实体类数据一起获取并返回。在确定要访问关联对象的情况下这些方法会提高很大的性能。
ToMany关联
@ToMany注解用来声明和一个集合的实体类的关联关系。需要放在用来关联实体类的List字段上。被关联的实体类需要有最少一个字段来指向用ToMany关联了自己的实体类。
下面有三种情况来构建映射关系,可以选取一个使用。
referencedJoinProperty 使用这个参数来指定目标实体类的外键,这个外键指向这个类的Id。
joinProperties 使用一个@JoinProperty的集合来实现更复杂的关联。每一个@JoinProperty都需要本类中一个字段和目标类中的一个关联字段。
@JoinEntity 如果要实现多对多关系,把这个注解放到指定多对多关联关系的关系表的字段上。
插件会自动的生成getter方法,用来获取被关联实体类的列表,如:
查询/更新ToMany关联关系
ToMany关联的查询都会被延迟加载,并在被首次调用时加载并缓存实体类到一个List,之后再次调用get方法就不再请求数据库了。
由于被关联的实体类列表是被缓存的,当被关联的实体类在数据库中新增时,这个缓存并不会更新,所以更新ToMany关系需要一些额外的处理。下面这段代码模拟了这个问题场景。
所以在新增被关联的实体类时,需要把它们手动的加入到主表类的关联列表中
同样的,也可以像这样删除被关联的实体类。
当有非常多的被关联对象呗添加、修改、删除时,可以用reset方法清除list的缓存,再次调用get方法时就会重新查询关联列表了。
1对多关系的双向关联
我们有时候会需要一对多关系的双向关联,在greendao中我们只能使用一个toOne和一个ToMany来实现。
接来下这段代码使用了之前用到的例子展示了如何对这个问题进行建模,这次使用了customerId字段来进行双向关联
假设我们有一个order对象,使用双向关联,我们可以拿到order的customer进而拿到customer的所有order。
例子:树形引用关系
我们可以在实体类中使用toOne和ToMany关系来构造一个树形的数据关系模型。
如此构建的实体类可以关联查询parent和children
触发构建代码
只有实体类被定义之后,就可以通过“Make project”来进行代码构建,或者直接执行gradle的greendao任务
如果修改实体类之后遇到了错误,尝试清除上次生成的代码并rebuild
修改构建的代码
greendao中使用到的实体类是由我们新增和编辑的,但是在greendao的代码构建中会在实体类中增加代码。
greendao会在构建后自动生成的方法和字段上增加@Generated注解来告知我们,以免造成代码丢失。因为每次构建greendao都会重新生成@Generated注解下的代码,所以我们应该尽量避免修改@Generated注解下的代码。
为了防止我们这样操作,当我们手动修改@Generated下的代码时,greendao会抛出一个异常。
这个错误信息告诉我们,我们有两个方法来解决这个问题。
- 还原我们修改过的@Generated下的代码,或者直接删除,下次构建的时候会再次自动生成。
- 使用@Keep注解代替@Generated,这个注解会告诉greendao不再覆盖这些代码。需要注意的是,这些修改可能破坏实体类之间的关联和greendao的整体框架。所以这个操作应该谨慎,建议使用单元测试来避免一些不要的麻烦。
Sessions
DaoSession类是由greendao动态构建生成的,属于greendao的核心接口。DaoSession提供给了开发者一些访问数据库的基础操作以及一批包含更完整数据库操作的DAO类。此外,sessions还管理了实体类的标识作用域(identity scope)。
DaoMaster和DaoSession
在app初始化时需要创建一个DaoMaster并且获取到一个DaoSession。
需要注意的是数据库链接属于DaoMaster,所以多个session引用着同一个数据库链接,因此可以非常快速的创建新的session。
但是每一个session都需要分配内存,通常是实体类的一个会话缓存。
标识作用域和会话缓存(Identity scope and session “cache”)
如果你有两个查询返回了同一个数据库对象,那么你是在操作几个java对象?一个还是两个?这个完全依赖于标识作用域。
greendao在默认情况下,多个查询会返回对同一个java对象的引用,比如,从User表中加载一个ID为42的User对象会,在两次查询中会返回同一个java对象。
这是实体类缓存的副作用,如果一个实体类对象仍然存在内存中(greendao在这里使用弱引用),那么这个实体类就不会再次构建,同时greendao也不再执行数据库查询来更新实体类的值。所以,这个对象会迅速的从会话缓存中返回。比从数据库查询快了一到两倍。
清除标识作用域
执行下面代码会清除session中的所有标识作用域,将不会有被缓存的对象被返回。
单独清除某个实体类的DAO的标识作用域
查询
查询操作会返回符合一定标准的实体类,在greendao中可以使用原始的sql语句进行查询,也可以使用QueryBuilder接口进行查询。
同时,greendao也支持查询结果懒加载(lazy-loading),这样可以在操作大量查询结果集合时节省内存提高效率,
QueryBuilder
使用sql语句有两个弊端,一是拼写比较麻烦,二是容易产生一些在运行时才会注意到的错误。
而greendao的QueryBuilder类让我们不但能够定制实体类的查询,也能够让我们在编译阶段就避免掉一些错误。
简单的条件查询:查询所有的以“Joe”为firstname的User,并以lastname倒序排序
嵌套条件查询 查询以“Joe”为firstname并且在1970年10月以后出生的User。
假设user的出生日期以年月日的形式分别存储在属性字段中,我们以稍微正式的形式表示这个查询条件:
用queryBuilder的话可以这样写
分页(Limit,Offset,Pagination)
在一些情况下,我们只需要查询结果的一部分,比如在你的用户界面只需要展示前十个元素。而在存在大量数据但是用where条件并不能起到限制作用的时候,分页查询则显得尤为重要。QueryBuilder提供了limit和offset方法。
limit(int) 限制查询结果返回列表的长度
offset(int) 设置返回结果列表的偏移位置,和limit方法一起使用。offset方法将从结果列表的开始部分跳过一些元素,而limit方法则从这个地方选取一定长度的元素作为查询结果,offset方法不能脱离limit方法单独使用。
自定义类型作为查询参数
通常情况下,greendao会把查询参数自动的映射为实际的查询条件,比如boolean类型会被映射为值为0或1的INTEGER类型,Date类型则会被映射为INTEGER(long)类型。
但是自定义类型并不会被映射,在buidquery时必须使用数据库中字段的类型作为查询条件。例如:枚举类型会被映射为int类型,那么在查询的时候也要使用int作为查询条件。
默认情况下greendao支持下面这些数据类型。
Convert注解和属性转换器
定制类型可以让实体类支持任何类型的属性字段。使用在自定义类型的字段上增加@Convert注解可以将他们映射为greendao支持的数据类型,同时也必须提供一个PropertyConverter的实现。
例如,你可能在实体类中定义了一个自定义类Color的color字段,并且想把它映射为一个Integer类型。
下面是一个枚举类型映射Integer类型的例子。
注意,如果在实体类中定义类型转换器或者自定义类型,这些类需要是static的。
不要忘记单独处理null值,通常情况下在转换器在转换null的时候也需要返回一个null
在这里类型转换器的数据库类型并不是原始的SQLite类型,而是greendao提供的java数据类型。强烈推荐使用便于转换的原始数据类型,如int,long,byte,array,String,等。
注意,为了性能考虑,greendao在转换类型时使用的是一个单例,确认类型转换器不要有其他参数的构造方法,同时也要是线程安全的,因为它可能被多个线程同时调用。
如何正确的转换枚举类型
枚举和实体类都是非常常用的数据类型,在必须用到枚举的情况下,这里有一些最佳实践:
不要依赖枚举类型的瞬间和名称 这两个都是不稳定的,可能会在你下次编辑枚举定义的时候被改变。
使用一个稳定的id 在枚举中定义一个integer或者String类型的属性,这个id将会是比较稳定的,可以使用这个id来映射数据库。
给未知的值定义一个省缺值 定义一个UNKNOWN枚举的值,用来处理null或者未知的值,这个可以处理一些情况让应用免于异常,例如一些被移除掉的枚举值。
Query中的自定义类型
QueryBuilder并不识别自定义类型,必须使用原始的数据类型来进行查询(例如在where参数中)。
Query 和 LazyList
Query类用来表示一个可以被多次执行的查询。在使用QueryBuilder的list()方法来获取查询结果时,QueryBuilder会在内部使用Query类。当想要多次执行同一个查询时,我们可以使用QueryBuilder的build()方法来创建一个不会立即执行的query。
greendao同时支持单个对象的和列表形式的查询结果。
当想要查询单个结果对象时可以调用Query或QueryBuilder的unique()方法,这个方法会返回单个对象或者在没有查询结果是返回null。如果你不想要结果为null的查询结果,可以使用uniqueOrThrow()方法来代替,这个方法会返回一个非空的对象或者抛出一个DaoException异常。
查列表结果可以使用下面这些方法
list() 所有实体类都会被加载到内存中。结果是一个简单的ArrayList,简单易用。
listLazy() 实体类在需要时才会被加载到内存中。list中的元素被初次访问时被加载并且加入缓存供以后访问,必须被关闭。
listLazyUncached 返回一个实体类的虚拟list,任何访问结果列表元素的操作都会从数据库中加载,必须被关闭。
listIterator 能够在使用时(懒加载)迭代加载结果列表,数据不会被缓存,必须被关闭。
listLazy(),listLazyUncached(),listIterator()三个方法都使用到了greendao的LazyList类。在访问时加载数据,并持有一个数据库cursor的引用。这也是为什么必须要保证关闭list/iterator的原因。(一般情况下放在try/finally中)
从listLazy()和listIterator中缓存的lazylist和lazyIterator在所有元素都被访问或者遍历后会自动的关闭。然而在列表没有被全部访问的情况下你仍需要手动的调用close方法。
多次执行查询
用QueryBuilder创建的query对象可以被重复的执行查询操作。这比创建重复的Query对象更加有效率。如果查询参数没有改变,你可以直接再次调用list/unique方法来进查询。
同时查询参数也可以被改变:
调用setParameter方法来修改query的参数,每个参数通过从0开的索引来定位,索引的顺序依据QueryBuilder中加入的顺序来定的。例如:
在多个线程中执行Query对象查询
如果使用Query在另外一个线程中执行查询,那么必须要调用forCurrentThread()方法来获取一个当前线程的Query实例。
Query对象绑定了Query对象被创建时的线程
这个设定让我们能够安全的设置Query对象的参数而不被其他线程干扰。如果在一个线程中尝试对绑定了另外一个线程的Query对象设置查询参数或者执行查询操作,会抛出一个异常。这样就不用声明synchronized块来防止多线程并发了,而事实上也应该避免使用locking,因为并发事务使用同一个Query对象时可能会造成死锁(deadlock)。
每次调用forCurrentThread()法时,查询参数会被设置为query被build时的原始的查询参数。
原始查询
当QueryBuilder提供不了你的需求的时候,有两个方法来执行原始的sql语句并且返回实体类对象。
一种是使用QueryBuilder和WhereCondition.StringCondition来进行请求,这种形式可以传入任何的sql片段作为Where条件。
下面是一个例子,只是示例,这种场景使用join方法会更好。
另外一种方法是不是用QueryBuilder,而是使用Dao对象的queryRaw或者queryRawCreate方法。这两个方法可以传入一行sql语句,这个sql会被拼接到Select和字段名后面。这种方法可以写入任何的where和orderby查询条件。可以使用别名T来对Entity表进行引用。
下面这个例子展示了如何创建Query,来查询group是admin的user。只是实例,这种场景使用join方法会更好。
PS:可以使用插件生成的常量来引用表和字段的名称。这个做法可以避免拼写错误。在一个实体类的DAO类中,可以找到名字叫做TABLENAME的常量保存了表的名称,内部类Properties包含了对应所有的属性字段的名称常量。
条件删除
批量删除不会单独删除实体类,而会删除所有满足条件的实体类。创建QueryBUilder,并执行buildDelete()方法获得DeleteQuery,
执行DeleteQuery就会执行批量删除操作。
注意,批量删除操作并不会影响到缓存中的实体类,例如你可以“复活”一个被缓存并且被通过id访问过的已经被删除的实体类。如果遇到这类问题可以通过清除缓存来解决。
查询故障排除
如果你的查询并没有返回你预期的结果,有两个静态标识可以打开QueryBuilder的Sql和参数的日志打印。
开启这个标识将会在build方法被调用时打印sql语句和传入的参数。可以将这些值和你实际预期的语句进行比较,也可以将这些拷贝到sql管理器中进行执行。
连表查询
一些特殊的查询需要从多个实体类(表)中查询数据库,在使用SQL的时候通过join操作符对两张过更多的表进行关联查询是常有的事情。
假设我们有一个User表,还有一个存在着一对多关系的Address表(一个User有多个Address)。然后我们要查询联系地址包含“Sesame Street”的所有User:我们必须把Address表和User表通过userId关联起来,并使用where条件来获得查询结果。
join()方法需要传入一个实体类的class和两个join用的字段名称作为参数。在上面这个例子中,只传入的Address的字段作为参数,因为默认情况下是使用主键作为Join左侧的字段名称。
QueryBuild中的Join方法
因为在使用主键作为join参数的时候是可以省略的,所以join存在了三个重载的方法。
多表联查
greendao允许链式的调用join来实现多张表的联查。可以在使用join的时候调用另外一个关联了表的join。这样第一个join的第二张表则作为第二join的第一张表来进行关联。
QueryBuilder的API是这样的
下面是一个关联了三张表的例子:City, Country, Continent。如果要查询欧洲中人口最少一百万的City:
联查本表/树形结构
join操作同时也可以用来关联单个实体类,例如我们要查询所有爷爷名称是“Lincoln”的Person。假设在Person表中有一个fatherId字段来指向同一张表中的某一个Person,查询可以这样写
正如上面看到的,join是一个非常强大的用来多表联查的方法。
数据库加密
greendao支持对一些含有敏感数据的数据库进行加密。
虽然新版本的Android系统支持文件系统加密,但是Android本身并没有提供对数据库文件的加密支持。所以如果攻击者拿到了对数据库文件的访问权限(比如里用安全漏洞或欺骗root设备的用户拿到root权限),那么攻击者就可以访问数据库文件中的所有数据。使用加密的数据库能带来额外的一层安全防护,防止攻击者直接读取数据库文件。
使用自定义的SQLite构建器
因为Android本身并不支持加密数据库,所以需要在apk中带上一个自定义的SQLite构建器。这个自定义的构建器包含了native代码,所以APK体积会增大几兆。
设置加密数据库
greendao支持SQLCipher对数据库进行加密。 SQLCipher是一个第三方的数据库构建器,使用256-bitAES加密。
添加SQLCipher依赖
数据库初始化
只需要在创建数据库的时候使用.getEncryptedWritableDb(
最终代码如下:
关于与kotlin插件一起使用
上文提到greendao的实体类注解只能使用java类,所以kotlin项目中的实体类需要用java类定义。
而在实际开发中会发现,kotlin的编译插件识别不到greendao插件生成的代码,而造成编译时提示找不到Dao、Session等类。
可以通过在build文件中加入如下配置解决此问题
附
本文内容依据于官方文档,部分为GreenDao官方文档直译。